Leaping Into Memories: Space-Time Deep Feature Synthesis
ICCV 2023
-
Vrije Universiteit Brussel & imec
Abstract
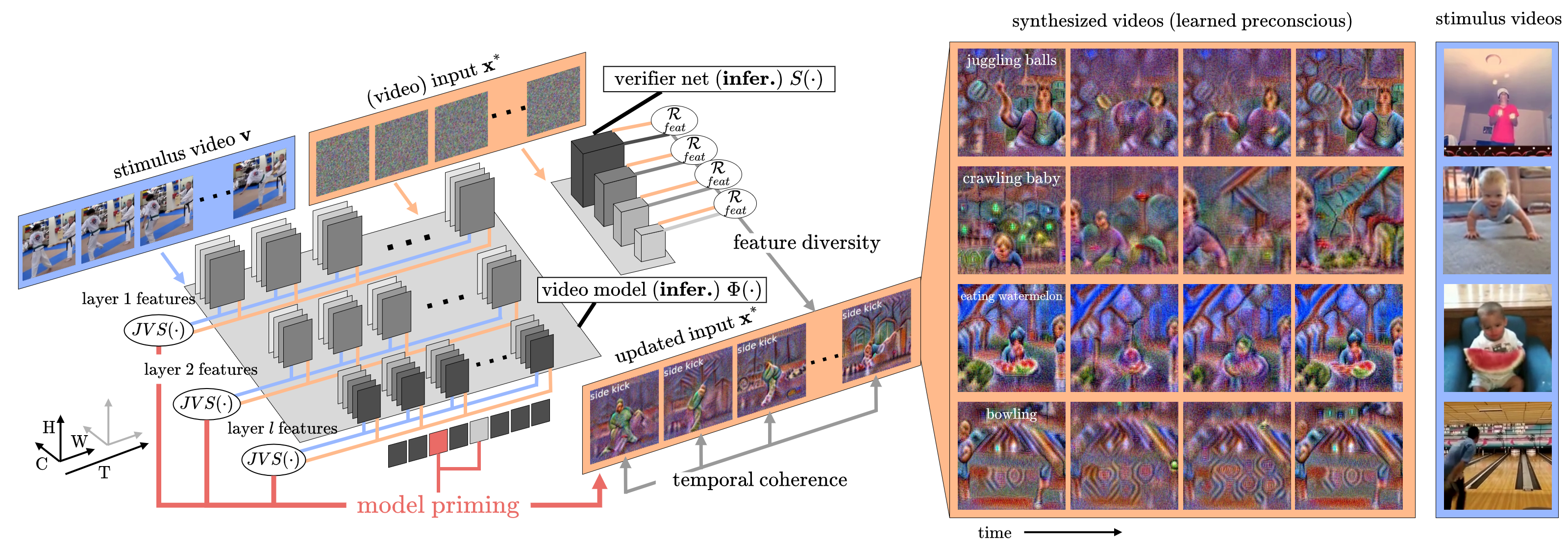
The success of deep learning models has led to their adaptation and adoption by prominent video understanding methods. The majority of these approaches encode features in a joint space-time modality for which the inner workings and learned representations are difficult to visually interpret. We propose LEArned Preconscious Synthesis (LEAPS), an architecture-independent method for synthesizing videos from the internal spatiotemporal representations of models. Using a stimulus video and a target class, we prime a fixed space-time model and iteratively optimize a video initialized with random noise. Additional regularizers are used to improve the feature diversity of the synthesized videos alongside the cross-frame temporal coherence of motions. We quantitatively and qualitatively evaluate the applicability of LEAPS by inverting a range of spatiotemporal convolutional and attention-based architectures trained on Kinetics-400, which to the best of our knowledge has not been previously accomplished.
Video overview
Synthesized videos
Use the arrows to navigate over synthesized videos from different inverted models.

Stimulus video
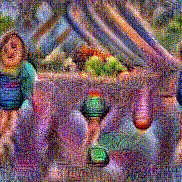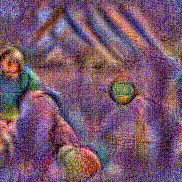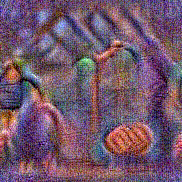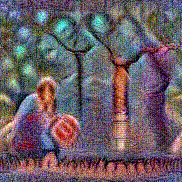
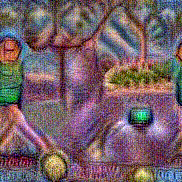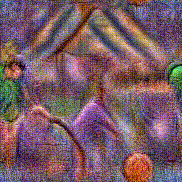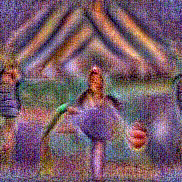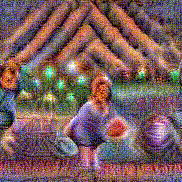

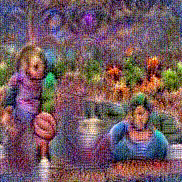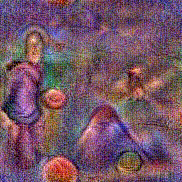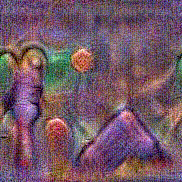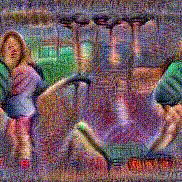
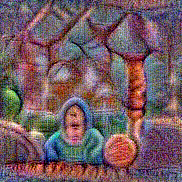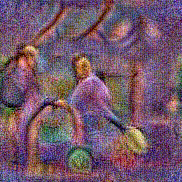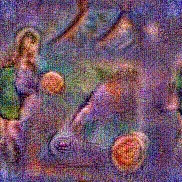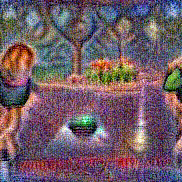
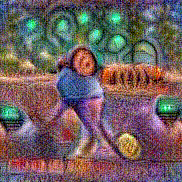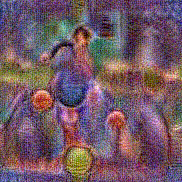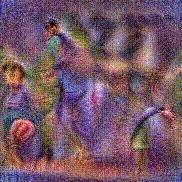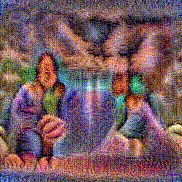
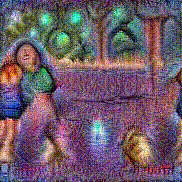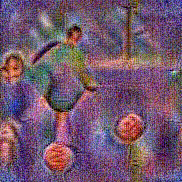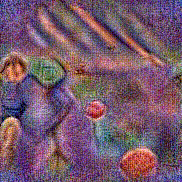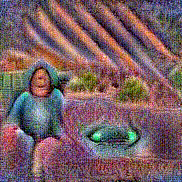
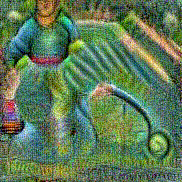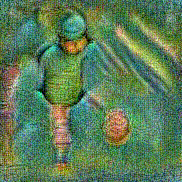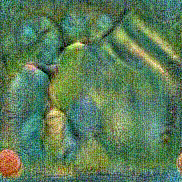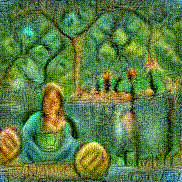
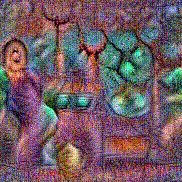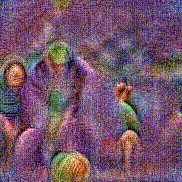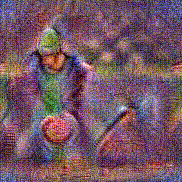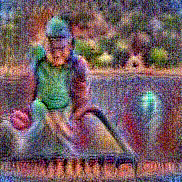
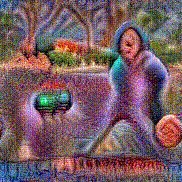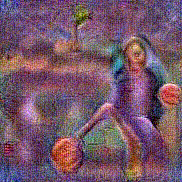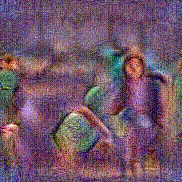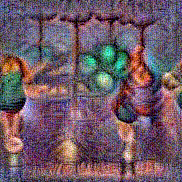
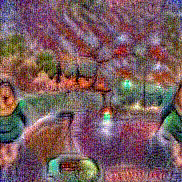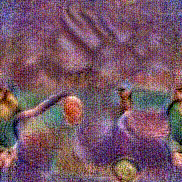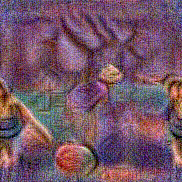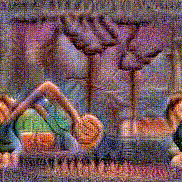
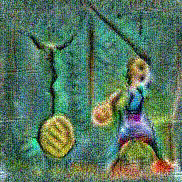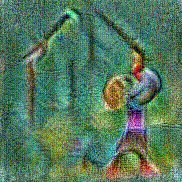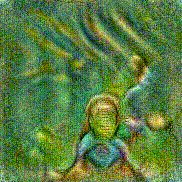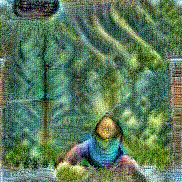
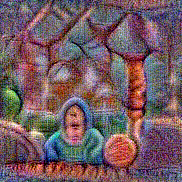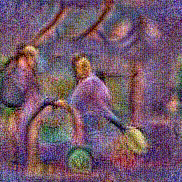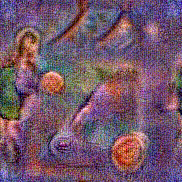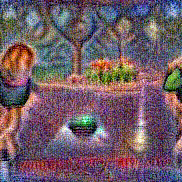

Stimulus video
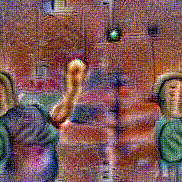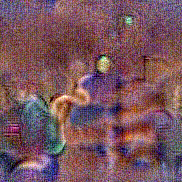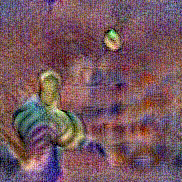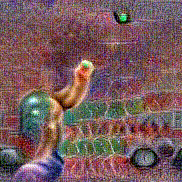
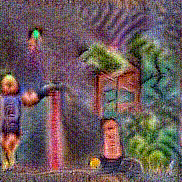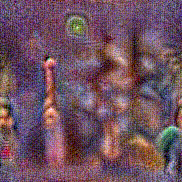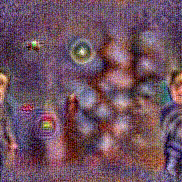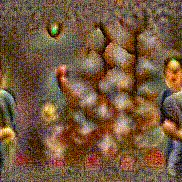
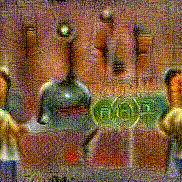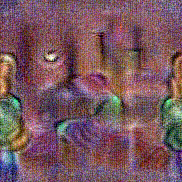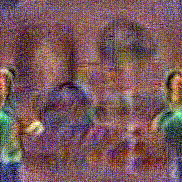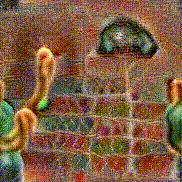
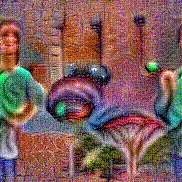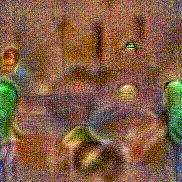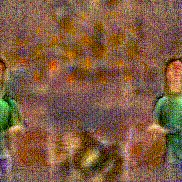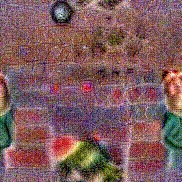
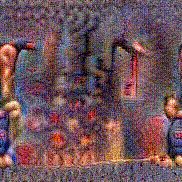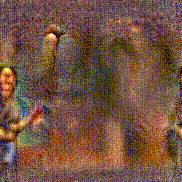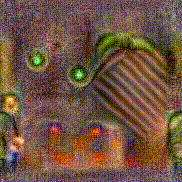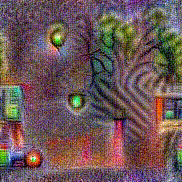
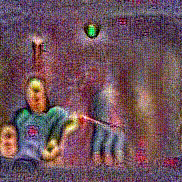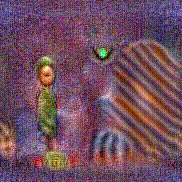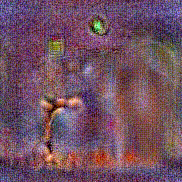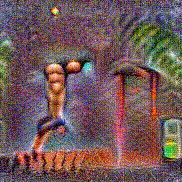
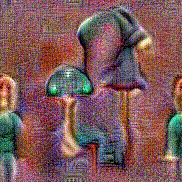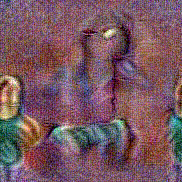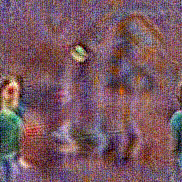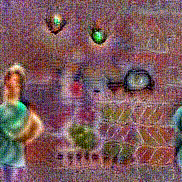
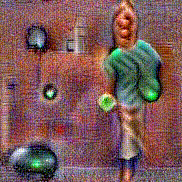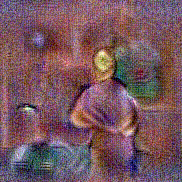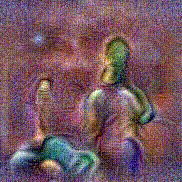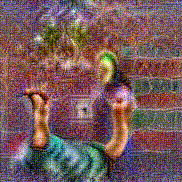
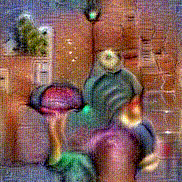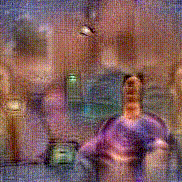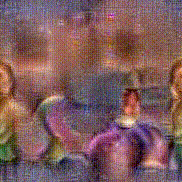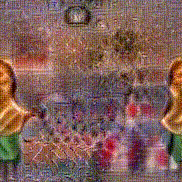
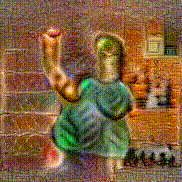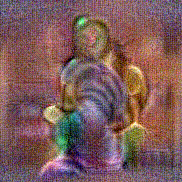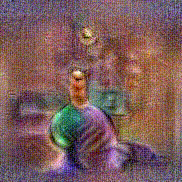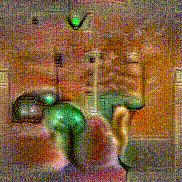
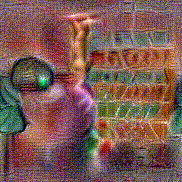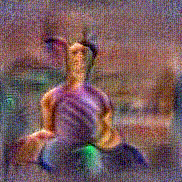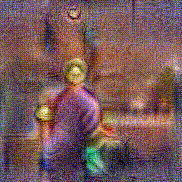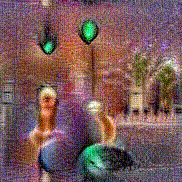
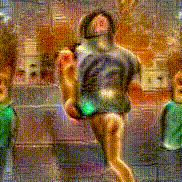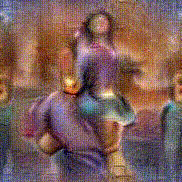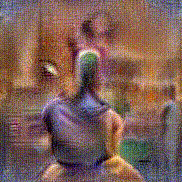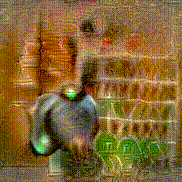

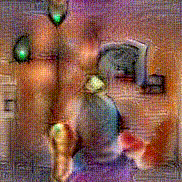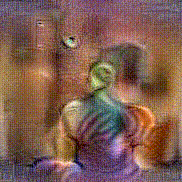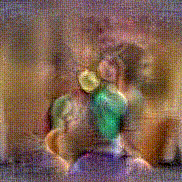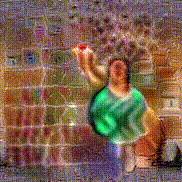
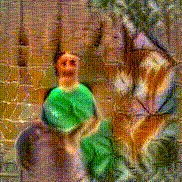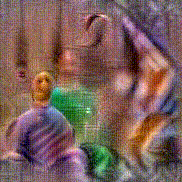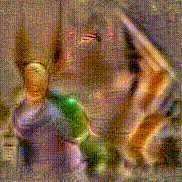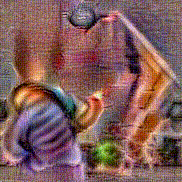
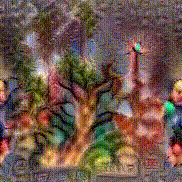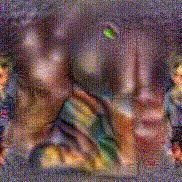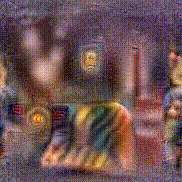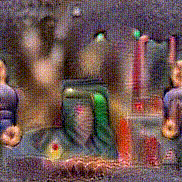

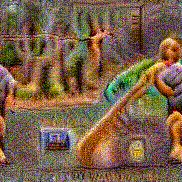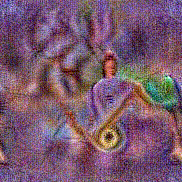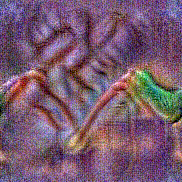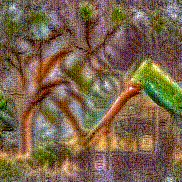
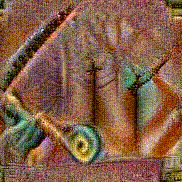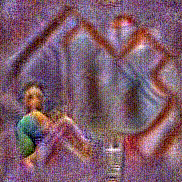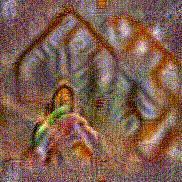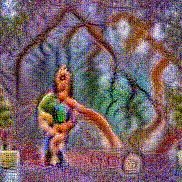
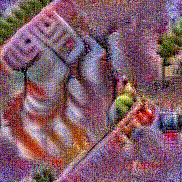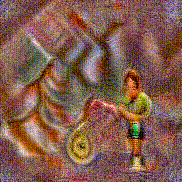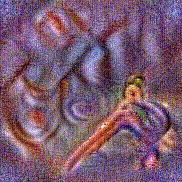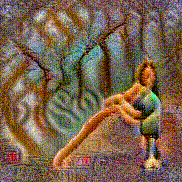

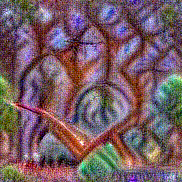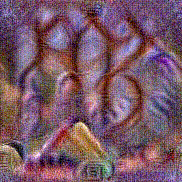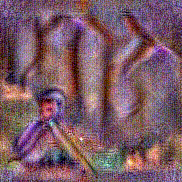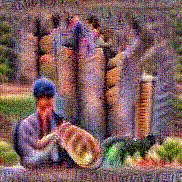

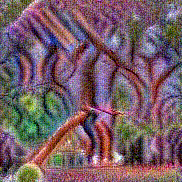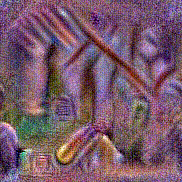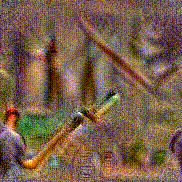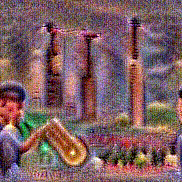
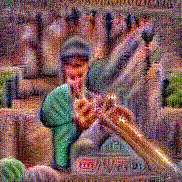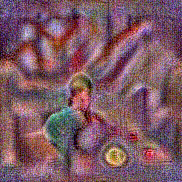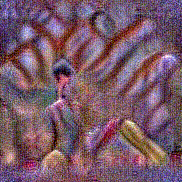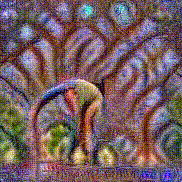


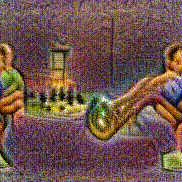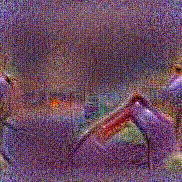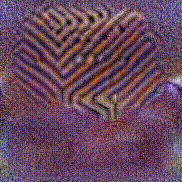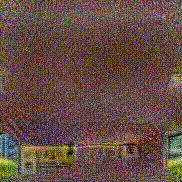
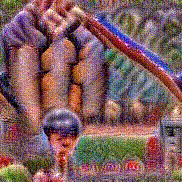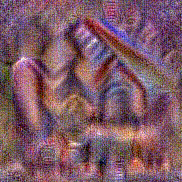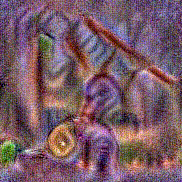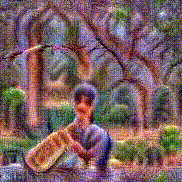



Method
Model priming
Motivated by visual priming in cognitive science, we demonstrate that learned representations of video models can become accessible through model priming. By using a video stimulus \( \mathbf{x} \) and a parameterized input \( \mathbf{x}^{*} \), we iteratively synthesize the dominant learned concepts corresponding to actions. We define a priming loss based on the difference between internal representations inferred from the stimulus video and those from the optimized across model layers. $$ \underset{prim}{\mathcal{L}}(\mathbf{x}^{*},\mathbf{v}) \! = \!\! \; \frac{1}{L} \sum_{l \in \mathbf{\Lambda}} \lambda_{l} \; JVS \left( \mu \!\left( \textbf{z}^{l}(\mathbf{x}^{*}) \right) \!,\mu \!\left(\textbf{z}^{l}(\mathbf{v})\right) \right) $$ where \( \mu \!\left( \textbf{z}^{l}(\mathbf{x}) \right) \) and \( \mu \!\left( \textbf{z}^{l}(\mathbf{x}^{*}) \right) \) are mean embeddings vectors for the stimulus and parameterized input for all layer \(l \in \mathbf{\Lambda} \) layers . We use denotes the Jaccard vector similarity \( JVS(\cdot) \) to compare them. Due to the vastness of the feature space when optimizing the input, we include two additional regularization terms as constraints.
Temporal Coherence Regularization
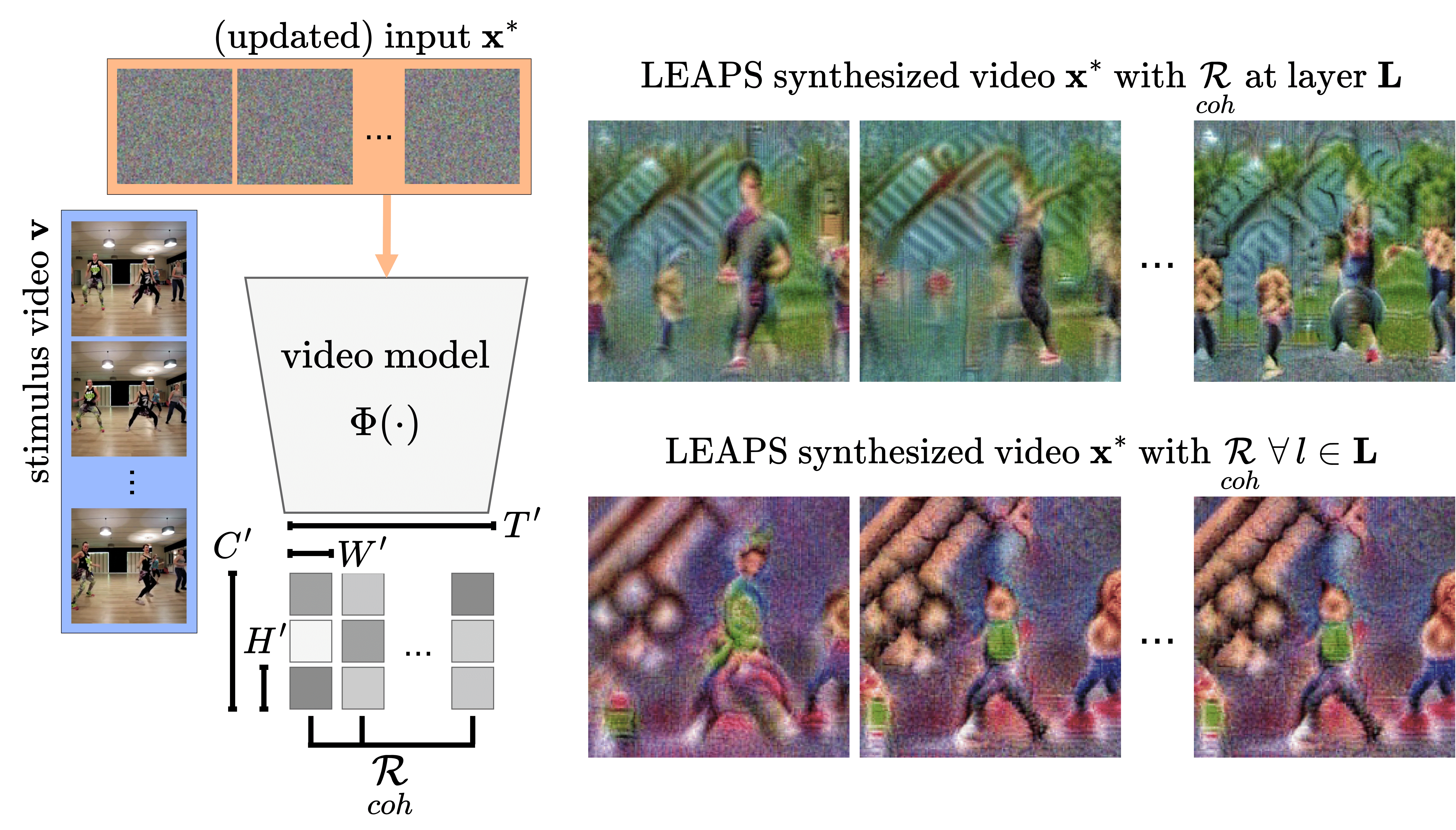
Feature Diversity Regularization
Despite priming providing a strong signal with which the input can be updated, the diversity of features is limited compared to observing multiple instances. Thus, class features varying from those in the stimulus, or features not present in the stimulus, may not be explored during optimization. To enhance the search space we include an additional domain-specific verifier network and feature diversity regularizer. We use the batch norm mean and variance to approximate the expected mean and variance.
The final LEAPS objective if formulated as the combination of model priming, temporal coherence, and feature diversity regularizers. $$ \mathcal{L}(\mathbf{x}^{*},\mathbf{v}, y) \! = \! \underset{CE}{\mathcal{L}}(\mathbf{x}^{*},y) + \underset{prim}{\mathcal{L}}(\mathbf{x}^{*},\mathbf{v}) + r \mathcal{R}(\mathbf{x}^{*}) $$